Hi, I’ve made some prossure testing on HiveMQ-CE, I found that single-writer-x thread cost so much CPU and MEM.
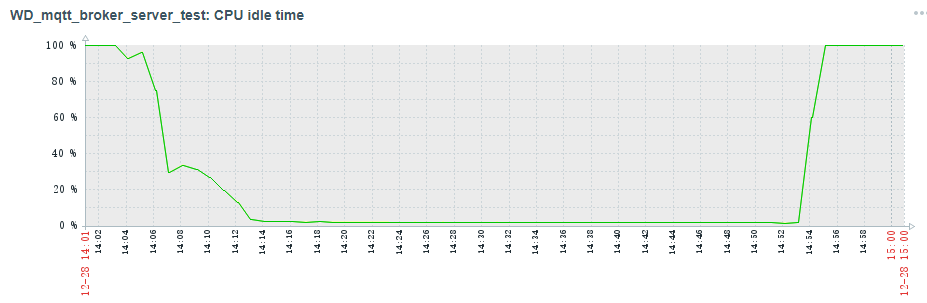
The server is 8C 32G ubuntu, I made 10k connections, then subscribe 5k topics, then publish to these topics at the rate of 22k QPS with Qos1. It performs well with 10min, but faded after 10min, I found the cpu idle time is almost to 0%, but another broker moquette works well.
Is it that xodus cannot support the QPS?
Tank you for starting this thread and adding some additional information.
Just to be clear:
As we can see from the result, the server seems not be able to support this QPS after about 10 mins
This may be true for your test setup on your test machine. Increasing the number of cores on your server will also increase the possible throughput.
Can you please add the following information:
What is the message size of your messages?
What is the topic structure you are using?
What’s the ratio of publisher to subscriber?
What are the numbers for incoming and outgoing PUBLISH packets, as seen by the broker?
Is there any noteworthy output in the files hivemq.log or event.log?
You mentioned:
If not otherwise specified, Moquette uses in-memory persistence:
#********************************************************************* #The file for the persistent store, if not specified, use just memory #no physical persistence
#********************************************************************* #persistent_store ./moquette_store.h2
HiveMQ CE comes with full file persistence. That means that all of the crucial data like: subscriptions, unfinished message flows, payloads or retained messages are persisted to file and can be migrated between servers or allow recovery without data loss in disaster scenarios.
Did you compare moquette in file persistence?
Did you investigate what kind of data is persisted in moquette and how well it can recovery from a disaster?
the topic strutcture like “/topic/{instanceId}/{num}”, where {instanceId} is a 6 byte fixed string, and {num} is an increasing number from 0 to 4999.
step1. I fistly made 10k connections and put them into a list, step2. then continuously subscribe the topic above with the first 5k clients, step3. then continuously(infinitely) publish to the 5k topics with clients of all this list. so is it that in this case the ratio of pub/sub will increase as the infinite publishing loop goes?
the clients just infinitely publish to the broker, so no certain numbers of packets.
sorry I didn’t keep the log file.
About Moquette:
I started to read the source code of Moquette after I posted this topic, and I found that Moquette actually persist the data in memory, so my puzzle solved. Data completeness and performance contradict to each other, it’s not easy for us to get both.
By the way, I really appreciate the code of HiveMQ, I think it’s well designed and written by experienced developers, so I just can’t believe it inferior to Moquette in my test result.