Good morning, I am testing Hive in the 2 modes performance and non and the performance is doing much better as expected. The issue I am having is I will have multiple serves and want to log off the server. We are in Amazon AWS so I have an EFS mount setup.
When I am logging local, clients stay connected for days, when I am lgging to the EFS, oddly the hive server is dumping a lot of them at one time. I did notice that the config had the new location setup, but the rotate rule had the local (so that didn’t work), but fixed that this am, but any other thoughts as I wait a day for this?
nice to see you evaluating HiveMQ. Can you please help me better understand what your are testing?
Are you using EFS exclusively to write logs to, or is your brokers’ entire installation mounted there?
If I understand correctly that you are seeing better performance in a single node versus a 2 node cluster, that can be explained by the fact that a 2-node cluster will perform “full replication”. This means all messages as well as session details (among other data) is replicated fully between both nodes, no matter where a client is connected. This is done to ensure high availability and rule out message loss should either node unexpectedly be lost. Depending on the configured replica count, this effect can be reduced quite considerably once you add further nodes to the cluster as only parts of the traffic are replicated to parts of the cluster while still offering guarantees during outages.
Thanks for the quick reply. What we are doing is have devices out in the world that are communicating into our amazon AWS world through a load balancer. We have 15+ mosquitto servers and not happy with the performance, there not accepting more than 2,000 devices even though the CPU and such are all low. Note the application and config are all location, only the event and hivemq logs are being written off the server, but as I mentioned, the config i didn’t realize had the rollover still pointing local, not sure if the log size contributed to the issue, but that is updated this AM and I am waiting to see today.
So I rolled out a hive instance and it beat that mosquito down bad, a base install of mosquitto had around 2,000 connections, where the quick install of hive had over 3.100. So we want to start to migrate those servers to the new hive platform. I put a second in there and started testing performance mode, and as you see, performance was even better, most of the time I can get the same device count with less CPU/RAM.
The next phase is to centralize logging so decelopers don’t need to goto one machine, then the next, but rather goto a shared place and see server1-event.log, server2-event.log (that naming is done with a boot script).
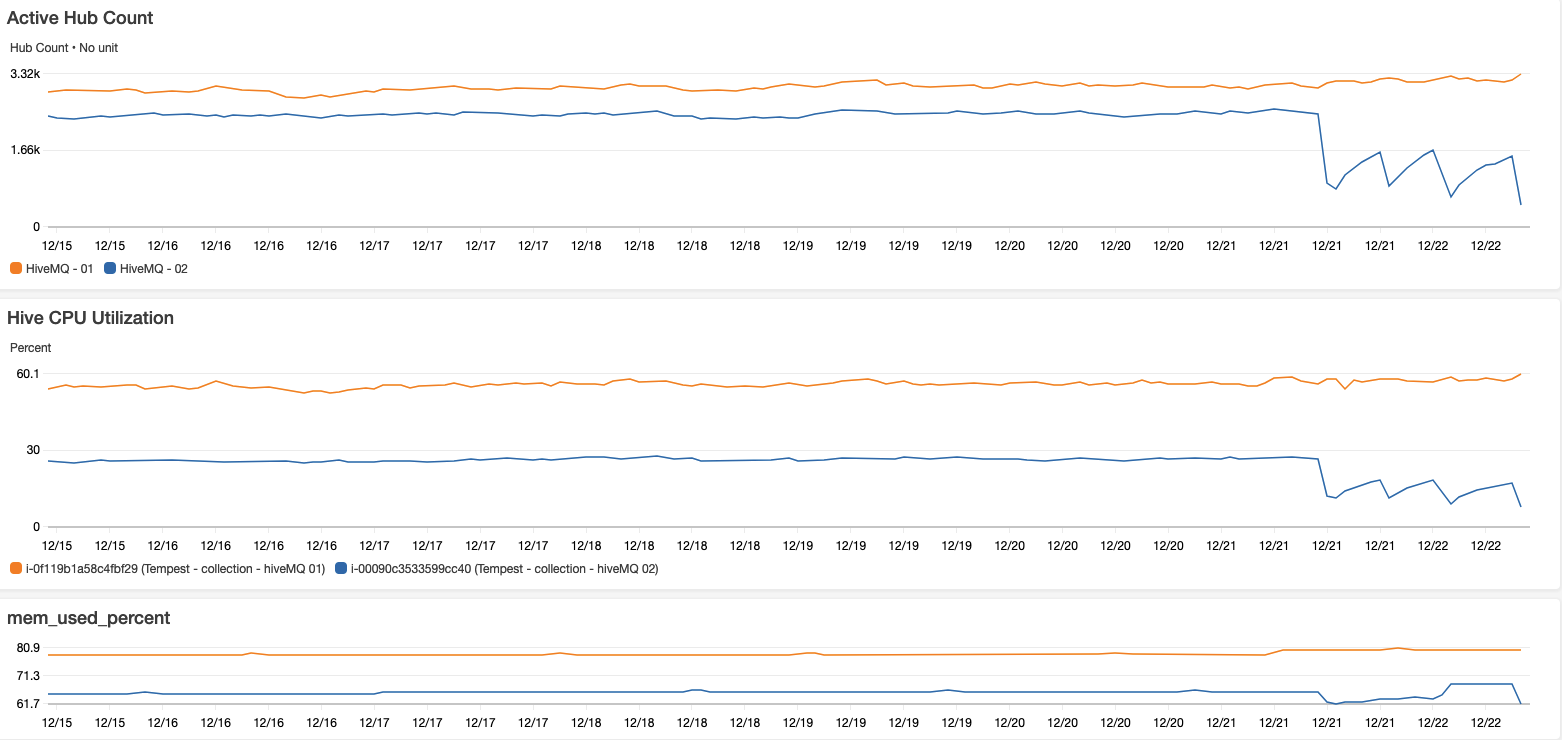
But what is noticed, when I switch from logging to the local disk and to the shared disk, on intervals, that node drops connections and almost starts over. So when you say they talk to each other, I am not using the pro/paid, cluster, etc. this is just 2 standalone machines on the same network. When the 2 are side by side there fine, performance mode, still good (much better than the first), but once I say log to a shared location that oddity happens.
Here is a week snapshot, and I can go back further, the only change was saying log to that share vs log local (and the log rotate was wrong). I am logging the diskIO to the EFS and not even touching 1% so it’s not an IO issue and there is just one machine that has it mounted so we know its not that either.
what instance type are you running HiveMQ on? Is it possible you are running into network limitations which could be playing a role here? It is not immediately obvious to us how logging to EFS would negatively affect broker operations.
Sorry for the delay, holidays a bit all over, but regardless thanks for the delay.
These are running on m5.large servers, ubuntu 20.04 with all the latest and greatest patches. I do agree its odd, the EFS I/O barely makes a blip so it’s not an IO issue.
I am welcome to test other thoughts/ideas, different instance types, etc. I can also try to mount an EBS volume for logging and see if I do the same, just a really odd one as we want to replace 15 mosquito nodes, but need the logs in a central place. Cloudwatch is good but a bit clunky, and when we need them we need them real time or I would look to just roll them hourly to the EFS.